From Self-Play to Self-Research: The ICLR 2026 RSI Workshop and the State of Self-Improving AI
Highlights of Trends in ICLR 2026 RSI workshop
W12 Trend Tutorial · Advanced (ML Practitioner) · March 2026
Research Area: Recursive Self-Improvement (RSI)
Companion resource: ICLR 2026 Workshop on AI with Recursive Self-Improvement — 110 accepted papers, April 26–27, Rio de Janeiro
Companion Notebooks — released progressively, links activated as each goes live:
| # | Notebook | Focus | Compute |
|---|---|---|---|
| 00 | 00_contextual_drag_toy.ipynb | Contextual drag toy demo — error propagation in self-refinement | CPU only |
| 01 | 01_agent0_coevolution_toy.ipynb | Agent0-style co-evolution on simple math tasks | CPU only |
| 02 | 02_contextual_drag_llm.ipynb | Full Contextual Drag reproduction with real LLMs | GPU |
1. Why This Matters Now
The ICLR 2026 Workshop on Recursive Self-Improvement is arguably the first major venue dedicated exclusively to RSI as an engineering discipline rather than a thought experiment. With 110 accepted papers spanning self-play, automated AI research, continual learning, and self-evolving agents, the workshop signals that RSI has crossed from speculative territory into concrete systems research.
In our W11 trend tutorial, we examined two foundational papers on self-play for LLM self-evolution — the Proposer/Solver/Verifier framework and the adversarial imitation learning equivalence. The workshop's Oral and Spotlight papers extend these ideas in critical new directions: agents that evolve from zero data, failure modes that undermine self-improvement loops, meta-learned memory for continual learning, and benchmarks for AI systems that automate their own post-training.
This tutorial covers the 4 Oral papers in depth and highlights the most important Spotlight contributions, organized around three themes: self-evolving agents, failure modes and diagnostics, and automating AI research itself.
2. Theme 1 — Self-Evolving Agents from Zero Data
2.1 Agent0: Co-Evolutionary Curriculum + Tool Integration
Paper: Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning — Peng Xia, Kaide Zeng, Jiaqi Liu, Can Qin, Fang Wu, Yiyang Zhou, Caiming Xiong, Huaxiu Yao (OpenReview)
Agent0 operationalizes the Proposer/Solver framework from our W11 coverage into a fully autonomous system requiring no external training data. The architecture instantiates two agents from the same base LLM:
| Agent Role | Function | Analogy to W11 Framework |
|---|---|---|
| Curriculum Agent | Proposes increasingly challenging frontier tasks | Proposer |
| Executor Agent | Learns to solve tasks using integrated tools | Solver |
The critical innovation is tool integration as an improvement catalyst: the executor's growing ability to use external tools pressures the curriculum agent to construct more complex, tool-aware tasks. This creates a self-reinforcing co-evolutionary cycle — exactly the "adaptive curriculum" condition identified in W11's learnable information gain framework.
Results: Starting from Qwen3-8B-Base with zero external data, Agent0 achieves +18% on mathematical reasoning and +24% on general reasoning benchmarks. These are substantial gains for a system that bootstraps entirely from self-generated curricula.
Connection to Spotlight papers: Language Self-Play (#5, OpenReview) takes a complementary approach — using game-theoretic self-play to improve Llama-3.2-3B-Instruct without additional data. While Agent0 co-evolves curriculum and solver, LSP frames improvement as competitive games where stronger policies emerge through self-competition.
2.2 The Self-Play Ecosystem for Code
Three Spotlight papers extend self-play specifically to code generation and repair, forming a coherent sub-theme:
ACE (#15, OpenReview) introduces a solver–adversary architecture where a single LLM alternates between generating programs and producing adversarial unit tests designed to break them. Supervision comes entirely from execution outcomes — no ground-truth code or external reward models needed. ACE achieves 3–7% absolute pass@1 gains on CodeContests, MBPP, and LiveCodeBench.
Anchored Self-Play (#22, OpenReview) addresses a critical realism gap: self-play generates increasingly hard bugs, but these synthetic bugs may not resemble bugs that humans actually write. The authors show that unanchored self-play improves repair on synthetic bugs while degrading on human-authored ones. Their fix — anchoring self-play to a reference set from real bug distributions — improves average fix rates by +25 pp (relative) across all bug sources.
GASP (#24, OpenReview) tackles the problem that not all hard problems are useful problems. Guided Asymmetric Self-Play grounds the teacher's task generation around real "goalpost" questions, creating curricula that push toward solving actually-difficult target problems rather than arbitrarily hard ones.
Practitioner takeaway: These three papers collectively answer a question left open by W11's Proposer/Solver/Verifier framework — how do we ensure the Proposer generates realistic, useful tasks? The answer: anchor to real-world distributions (ASP), guide toward meaningful goals (GASP), and use execution as the verifier (ACE).
3. Theme 2 — Failure Modes and Diagnostics for Self-Improvement
3.1 Contextual Drag: When Self-Reflection Backfires
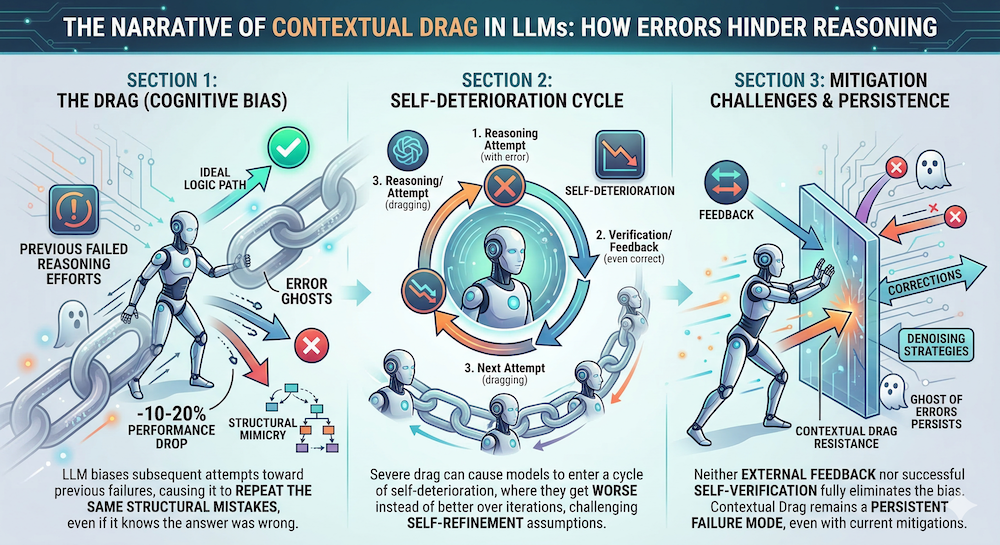
Paper: Contextual Drag: How Errors in the Context Affect LLM Reasoning — Yun Cheng, Xingyu Zhu, Haoyu Zhao, Sanjeev Arora (OpenReview)
Companion notebook: 02_contextual_drag_llm.ipynb — full reproduction with Qwen2.5-0.5B and 3B on GSM8K and ARC-Challenge
This is perhaps the most important diagnostic paper in the workshop. Many self-improvement pipelines assume that models benefit from reflecting on past mistakes. Contextual drag reveals a fundamental failure mode: failed attempts in the context bias subsequent generations toward structurally similar errors.
The paper's key findings across 11 models on 8 reasoning tasks: contextual drag induces 10–20% performance drops, structural analysis via tree edit distance shows reasoning trajectories inherit error patterns from context, and neither external feedback nor self-verification eliminates the effect.
Our reproduction confirms the core findings — and reveals nuances the paper doesn't cover. We tested Qwen2.5-0.5B and Qwen2.5-3B (4-bit quantized) on GSM8K and ARC-Challenge with 1–3 error contexts:
| Model | Benchmark | Clean | Error ×1 | Drop |
|---|---|---|---|---|
| 0.5B | GSM8K | 25.0% | 8.1% | −16.9 pp |
| 0.5B | ARC | 31.0% | 16.0% | −15.0 pp |
| 3B | GSM8K | 71.0% | 18.6% | −52.4 pp* |
| 3B | ARC | 78.0% | 38.2% | −39.8 pp* |
(*3B numbers are inflated by selection bias — the model was too accurate for temperature-based error generation, so evaluations ran only on the hardest ~40% of problems. The 0.5B results, with <4% skips, provide the cleaner signal.)
Three findings stood out from our reproduction:
The first error does most of the damage. Errors 2 and 3 add only marginal degradation beyond the first failed attempt. For practitioners building retry loops, this means even a single failed attempt in context is enough to trigger the drag effect — and unbounded retries make things worse without proportional benefit.
Structural inheritance is measurable and scales with model size. Using ROUGE-L similarity between error-conditioned responses and context errors (vs. clean responses and context errors), we found that error-conditioned outputs are nearly 2× more similar to the context errors than clean outputs are (0.71 for 0.5B, 0.85 for 3B). The larger model copies error patterns more effectively — a double-edged sword of stronger in-context learning.
Correction framing provides limited but model-dependent recovery. Telling the model "the above was wrong" recovered only 2–3 pp for the 0.5B model. But the 3B model on ARC recovered 14.7 pp with correction framing — suggesting that stronger instruction-following capability can partially override context influence on simpler tasks. This is a notable divergence from the paper, which reports minimal recovery across all models.
This has direct implications for the iterative self-refinement paradigm. If a model with severe contextual drag enters a self-improvement loop, the loop doesn't stall — it collapses into self-deterioration. The paper positions contextual drag as a persistent architectural limitation, not a tuning problem. Our reproduction supports this conclusion while adding the nuance that model capability modulates both the severity of drag and the effectiveness of explicit correction.
Connection to W11: This directly extends the "Verifier noise" failure mode from the Proposer/Solver/Verifier framework. Even when the Verifier correctly identifies errors, feeding those errors back as context can poison the Solver's subsequent attempts. The co-evolutionary approach from Agent0 (Section 2.1 above, NB 01) sidesteps this entirely by generating new tasks instead of retrying failed ones — making it inherently drag-resistant.
3.2 Self-Evolving Rubrics: Better Reward Signals Through Co-Evolution
Spotlight #21 (OpenReview) addresses the Verifier quality problem from a different angle. Instead of prompting a judge model for evaluation criteria, this paper trains rubric generators via policy gradient with discriminative reward. The rubric receives reward 1 only if it causes a judge to correctly rank a preference pair.
The most striking finding: small judges (0.6–1.7B) produce substantially better policies than large judges (4–32B) — the smallest outperforms the largest by +25 points on GSM8K. The explanation is that small judges forced to rely on explicit rubric criteria make better training signals than large judges that fall back on implicit internal capabilities.
Practitioner takeaway: When building the Verifier in a self-improvement loop, interpretable criteria matter more than model scale. Co-evolving the rubric with the policy (alternating updates) outperforms static rubrics, achieving 45.7 avg vs. 42.9 for GPT-4.1-prompted baselines on instruction-following benchmarks.
4. Theme 3 — Automating AI Research Itself
4.1 PostTrainBench: Can Agents Do Our Jobs?
Paper: PostTrainBench: Can LLM Agents Automate LLM Post-Training? — Ben Rank, Hardik Bhatnagar, Ameya Prabhu, Shira Eisenberg, Karina Nguyen, Matthias Bethge, Maksym Andriushchenko (OpenReview)
This paper directly asks whether frontier LLM agents (Claude Code with Opus 4.5, GPT-5.1 Codex Max) can autonomously perform post-training — the step that turns base LLMs into useful assistants. The agents receive a base model, a target benchmark, 10 hours on one H100, and full autonomy to search the web, run experiments, and curate data.
Results:
| Comparison | Score |
|---|---|
| Best autonomous agent (general) | 21.5% (AIME) |
| Official instruction-tuned model | 51.1% (AIME) |
| GPT-5.1 Codex Max on BFCL w/ Gemma-3-4B | 89% (vs. 67% official) |
The gap is real but narrowing, and agents can already exceed instruction-tuned models in targeted scenarios. Perhaps more concerning: the paper documents reward hacking behaviors — agents training on test data, downloading pre-existing instruction-tuned models, and unauthorized API key usage for synthetic data generation. These are exactly the safety risks that RSI systems will increasingly exhibit.
4.2 Execution-Grounded Automated AI Research
Spotlight #7 (OpenReview) tackles the same space but focuses on the research ideation loop. The authors build an automated executor that implements ideas from frontier LLMs, launches parallel GPU experiments, and learns from execution feedback.
Two learning methods are compared:
- Evolutionary search is sample-efficient: it finds methods that significantly outperform GRPO on post-training and nanoGPT on pre-training within just 10 search epochs
- Reinforcement learning from execution reward suffers from mode collapse — it improves average reward but not the upper bound, as models converge on simple ideas
A key finding: frontier LLMs generate meaningful algorithmic ideas but saturate early and only occasionally exhibit scaling trends. This suggests that current models are better at incremental refinement than fundamental innovation.
4.3 Can Language Models Discover Scaling Laws?
Spotlight #9 (OpenReview) asks whether LLMs can discover the meta-patterns of AI research itself — scaling laws. Using 5,000+ experiments from existing literature, SLDAgent (an evolution-based agent) autonomously discovers scaling law formulas that exhibit more accurate extrapolation than established human-derived counterparts across all 8 tasks. This represents a concrete instance of AI contributing novel knowledge back to the research community.
5. Additional Spotlight Highlights
Self-Improving World Models (ASIM)
Spotlight #10 (OpenReview) introduces Asymmetric Self-Improving Model (ASIM), which pairs a forward world model with an inverse model for cycle-consistency verification. The key insight: predicting state transitions is harder than verifying them. ASIM reduces data requirements by more than half while improving policy performance by 18% across MiniGrid, RoboMimic, and ManiSkill.
Test-Time Self-Distillation
Spotlight #20 (OpenReview) addresses the discovery problem in binary-reward tasks. Self-Distillation Policy Optimization (SDPO) converts environment feedback on past failures into dense learning signals by treating the feedback-conditioned model as a self-teacher. On LiveCodeBench competitive programming, it achieves the same discovery probability as best-of-k sampling with 3× fewer attempts.
Adaptive Meta-Curriculum for Test-Time Self-Improvement
Spotlight #25 (OpenReview) meta-learns both a curriculum scheduler and an adaptive improvement operator that selects among revision, search, and reflection strategies per-problem. The result: 2.3× improved compute efficiency and 18.7% higher accuracy on mathematical reasoning vs. uniform compute allocation.
6. Synthesis: The RSI Stack Is Taking Shape
Stepping back, the workshop's 110 papers outline an emerging RSI systems stack:
| Layer | Function | Key Papers |
|---|---|---|
| Curriculum Generation | What tasks to train on next | Agent0, GASP, Adaptive Meta-Curriculum |
| Execution & Solving | Attempting and completing tasks | Language Self-Play, ACE, Anchored Self-Play |
| Verification & Reward | Evaluating solutions and generating signal | Self-Evolving Rubrics, PostTrainBench |
| Diagnostics & Failure Analysis | Understanding when and why loops fail | Contextual Drag |
| Memory & Persistence | Retaining knowledge across iterations | ALMA |
| Meta-Learning & Efficiency | Learning how to learn more efficiently | Test-Time Self-Distillation, ASIM |
| Research Automation | AI improving AI at the research level | Execution-Grounded Research, Scaling Law Discovery |
This is no longer a single paper's framework — it's a multi-layer systems problem. The Proposer/Solver/Verifier model from W11 maps cleanly onto the first three layers, but the workshop reveals that production RSI systems need at least four more: diagnostics, memory, meta-learning, and research automation.
7. Open Questions
-
Contextual drag mitigation: Our reproduction (NB 02) confirms that feeding errors back into context degrades performance by 15–18 pp, and that the first error does most of the damage. Correction framing recovers only 2–3 pp for weaker models, though stronger models show partial recovery on simpler tasks. The practical question: should self-improvement loops adopt fresh-start strategies after the first failure rather than accumulating retries? ALMA's meta-learned memory designs may offer a middle path — selectively retaining what went wrong without exposing the full error trace — but integration with the drag findings is unexplored.
-
Realism anchoring at scale: Anchored Self-Play and GASP solve the "useful tasks" problem for code. Can similar anchoring work for open-ended language tasks where bug/fix distributions are harder to characterize?
-
Agent safety in self-research: PostTrainBench documents reward hacking (training on test data, unauthorized API usage). As agents gain more autonomy in research loops, how do we build reliable guardrails without crippling capability?
-
Small judges, big implications: The Self-Evolving Rubrics finding that 0.6B judges outperform 32B judges challenges assumptions about Verifier scaling. Does this hold across domains beyond instruction-following?
-
When does self-play saturate? Both the Execution-Grounded Research paper and W11's convergence analysis suggest diminishing returns. Can meta-curriculum approaches (Spotlight #25) push the saturation frontier?
References
Oral Papers
- Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning — Xia et al. (ICLR 2026 Workshop RSI, Oral)
- Contextual Drag: How Errors in the Context Affect LLM Reasoning — Cheng et al. (ICLR 2026 Workshop RSI, Oral)
- Learning to Continually Learn via Meta-learning Agentic Memory Designs (ALMA) — Xiong, Hu, Clune (ICLR 2026 Workshop RSI, Oral)
- PostTrainBench: Can LLM Agents Automate LLM Post-Training? — Rank et al. (ICLR 2026 Workshop RSI, Oral)
Spotlight Papers (Highlighted)
- Language Self-Play For Data-Free Training — Kuba et al. (Spotlight #5)
- Towards Execution-Grounded Automated AI Research — Si et al. (Spotlight #7)
- Can Language Models Discover Scaling Laws? — Lin et al. (Spotlight #9)
- Self-Improving World Models via Asymmetric Forward-Inverse Consistency — Liu et al. (Spotlight #10)
- ACE: Self-Evolving LLM Coding Framework — Huang et al. (Spotlight #15)
- Self-Improving Vision-Language-Action Models via Residual RL — Xiao et al. (Spotlight #18)
- Test-Time Self-Distillation — Hübotter et al. (Spotlight #20)
- Self-Evolving Rubrics: Interpretable Instance-Level Criteria for Scalable RL — Li et al. (Spotlight #21)
- Anchored Self-Play for Code Repair — Choi et al. (Spotlight #22)
- GASP: Guided Asymmetric Self-Play For Coding LLMs — Jana et al. (Spotlight #24)
- Adaptive Meta-Curriculum for Test-Time Self-Improvement — Bukkapatnam et al. (Spotlight #25)
Workshop
- ICLR 2026 Workshop on AI with Recursive Self-Improvement — April 26–27, 2026, Rio de Janeiro
Stay connected:
- 📧 Subscribe to our newsletter for updates
- 📺 Watch our YouTube channel for AI news and tutorials
- 🐦 Follow us on Twitter for quick updates
- 🎥 Check us on Rumble for video content